TIGER Korpus
- Typ
-
Corpus
- Beschreibung
-
The TIGER Corpus (versions 2.1 and 2.2) consists of app. 900,000 tokens (50,000 sentences) of German newspaper text, taken from the Frankfurter Rundschau. The corpus was semi-automatically POS-tagged and annotated with syntactic structure. Moreover, it contains morphological and lemma information for terminal nodes. For details, see the annotation section. Version 2.2 is a cleaned up version of release 2.1.
The TIGER Corpus is delivered in two treebank formats:
- Negra export format (text format -- not available for TIGER Treebank 2.2)
- TIGER-XML format (XML-based format, see also TigerXML.xsd)
Both versions of the corpus can be processed by the treebank query tool TIGERSearch, which has also been developed within the TIGER project.
Version 1 of the TIGER Corpus is still available as well. It consists of app. 700,000 tokens (40,000 sentences). With respect to version 2, it lacks the morphological and lemma information.
In addition to the TIGER Corpus proper, several resources derived from it are available. These are:
- TIGER 2.2-doc which includes a full mapping of sentences to documents
- TIGER Corpus 2.2 converted into CoNLL-2009 dependency trees (by the tool Tiger2Dep)
- the TIGER 10.000 MOD Bank, which includes the first 10,000 sentences from the TIGER Corpus 2.1, where the original POS tags have been replaced by new tags that provide a more fine-grained analysis of modification in German,
- the TiGer Dependency Bank, which is a dependency-based gold standard for (hand-crafted) German parsers for the TIGER Corpus sentences 8,001 through 10,000,
- the TIGER 700 RMRS Bank,
- the TIGER data sets for the CoNLL-X shared task and
- dependency triple representations for (almost) the entire treebank, which, like the TiGer DB structures, are intended for evaluation purposes.
- Referenz
-
- Brants, Sabine, Stefanie Dipper, Peter Eisenberg, Silvia Hansen, Esther König, Wolfgang Lezius, Christian Rohrer, George Smith, and Hans Uszkoreit. 2004. TIGER: Linguistic Interpretation of a German Corpus. Journal of Language and Computation, 2004 (2), 597-620.
- TIGER Project. 2003. TIGER Annotationsschema. Manuscript. Universität des Saarlands, Universität Stuttgart Universität Potsdam. July 2003.
- Download
-
1. Research and evaluation purposes
For research and evaluation purposes, the TIGERCorpus can be downloaded for free. However, we ask you to acknowledge the TIGERCorpus license agreement for non-commercial use, first. The "Accept license terms" button at the bottom of the license text will then take you to the download page.
2. Commercial purposes
Currently (since Sept. 2020), the commercial license of the TIGERCorpus is under review (among other topics, to make it freely accessible, if possible). Please re-visit this page for updates.
- Kontakt
-
CLARIN-D Stuttgart (clarin AT ims.uni-stuttgart.de)
Annotation
The TIGER project aims to produce a large syntactically annotated corpus of German newspaper text. In order to yield a high-quality and theoretically well-founded annotation of the corpus, detailed annotation guidelines have been developed:
The file samples.tgz contains a short extract from the corpus. It contains the files:
- sample1.export : Negra export format (Release 1)
- sample1.xml : TIGER-XML format (Release 1)
- sample2.export : Negra export format (Release 2)
- sample2.xml : TIGER-XML format (Release 2)
Here is the graphical representation of a single corpus sentence:
- JPG format (Release 1, Annotate)
- Postscript format (Release 1, Annotate)
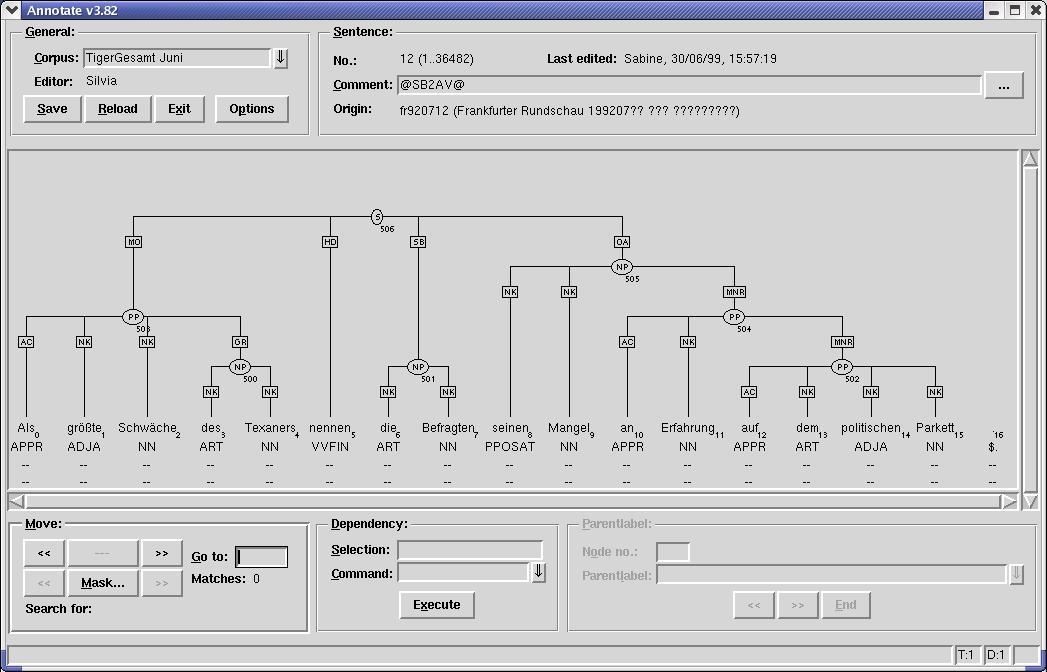{kind=link}
- JPG format (Release 2, TIGERGraphViewer)
- PDF format (Release 2, TIGERGraphViewer)
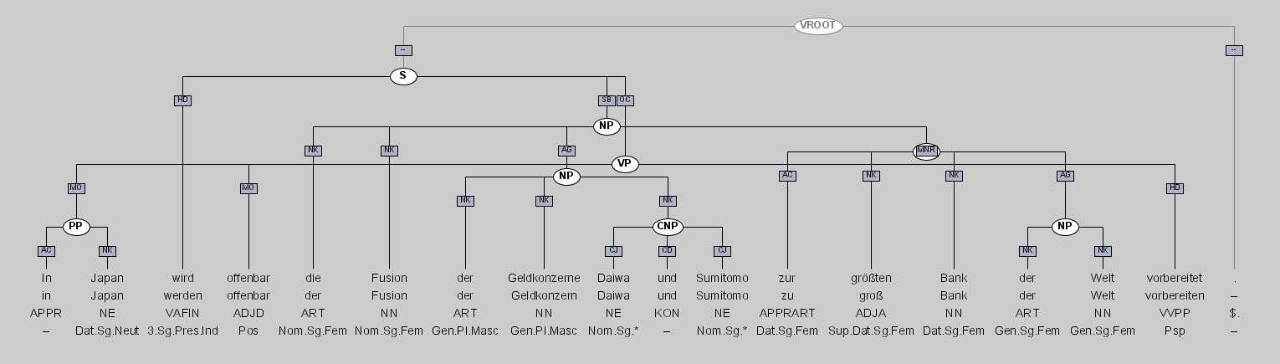{kind=link}
The quality (in terms of consistency) and the speed of the manual annotation are improved with the help of automatic annotation tools. For the annotation of the TIGER corpus, we are using two different approaches:
- Annotate
The major part of the TIGER corpus annotation is carried out by means of the Annotate software. Annotate is a graphical tool for efficient semi-automatic annotation of corpus data. In the framework of the TIGER project, the tool includes a partial parser and a part-of-speech tagger for the automatic partial corpus annotation. Annotate was developed in the NEGRA project at the University of Saarbrücken. For more information about Annotate, see the Annotate homepage and the LREC'2000 paper by Brants/Plaehn (ps.gz, pdf).
- LFG Annotation
In parallel to the Annotate tool, a broad coverage symbolic LFG grammar - developed in the Pargram project at the University of Stuttgart - is used for annotating the TIGER corpus. Annotation by the LFG grammar involves two steps which are now illustrated by examples (Please follow the links.):
- LFG parsing: First the TIGER corpus is parsed by the LFG grammar. The output of the LFG grammar is disambiguated semi-automatically.
- TIGER transfer: The selected output is then automatically converted to the TIGER export format.
This section gives a short introduction about LFG parsing and disambiguation. For a more detailed description see the LINC'2000 paper by Dipper (ps.gz, pdf).
Parsing
The German grammar applied in parsing is a Lexical Functional Grammar (LFG) and was developed in the Pargram project, using the Xerox Linguistic Environment (XLE).
In the context of the TIGER project we investigate the possibilities and limits of grammar-based treebanking. Currently, 35% of real newspaper text is successfully analyzed by the grammar.
The analysis an LFG grammar yields for a given sentence consists of two representations, the constituent structure (c-structure), and the functional structure (f-structure). C-structure encodes information about morphology, constituency, and linear ordering. F-structure represents information about predicate argument structure, about modification, and about tense, mood, etc.
Disambiguation
Most of the sentences of the TIGER corpus are syntactically ambiguous. Hence the grammar output has to be disambiguated before being mapped to the TIGER format. We use two different methods for disambiguation.
Automatic disambiguation: XLE provides a (non-statistical) mechanism for suppressing certain ambiguities automatically. The mechanism consists of a constraint ranking scheme inspired by Optimality Theory (OT). Grammar rules and lexicon entries can be marked by so-called OT marks. Highly improbable or marked readings are filtered out, thus reducing the number of ambiguities the human disambiguator has to deal with.
Manual disambiguation: Remaining ambiguities must be resolved manually. XLE supports manual disambiguation by packing all different readings into one complex representation that can easily be browsed by the human annotator. An example can be found here.
Without using the OT filter mechanism a sentence gets 35,577 analyses on average (median: 20). After OT filtering, the average number of analyses drops to 16.5 (median: 2).
Projekt CLARIN-D
- Weitere Informationen
- E-Mail schreiben
- Funktionsadresse