Cross-lingual Compound Identification (XCID)
- Type
-
Tool
- Author
-
Patrick Ziering
- Description
-
This system is a cross-lingual compound identification method based on cross-lingual evidence as given in parallel corpora. The method can work on any parallel corpus which is tranformed into a basic format.
The identification procedure, as described in Ziering and Van der Plas (2014) [1] and Ziering (2018) [2], is shown below: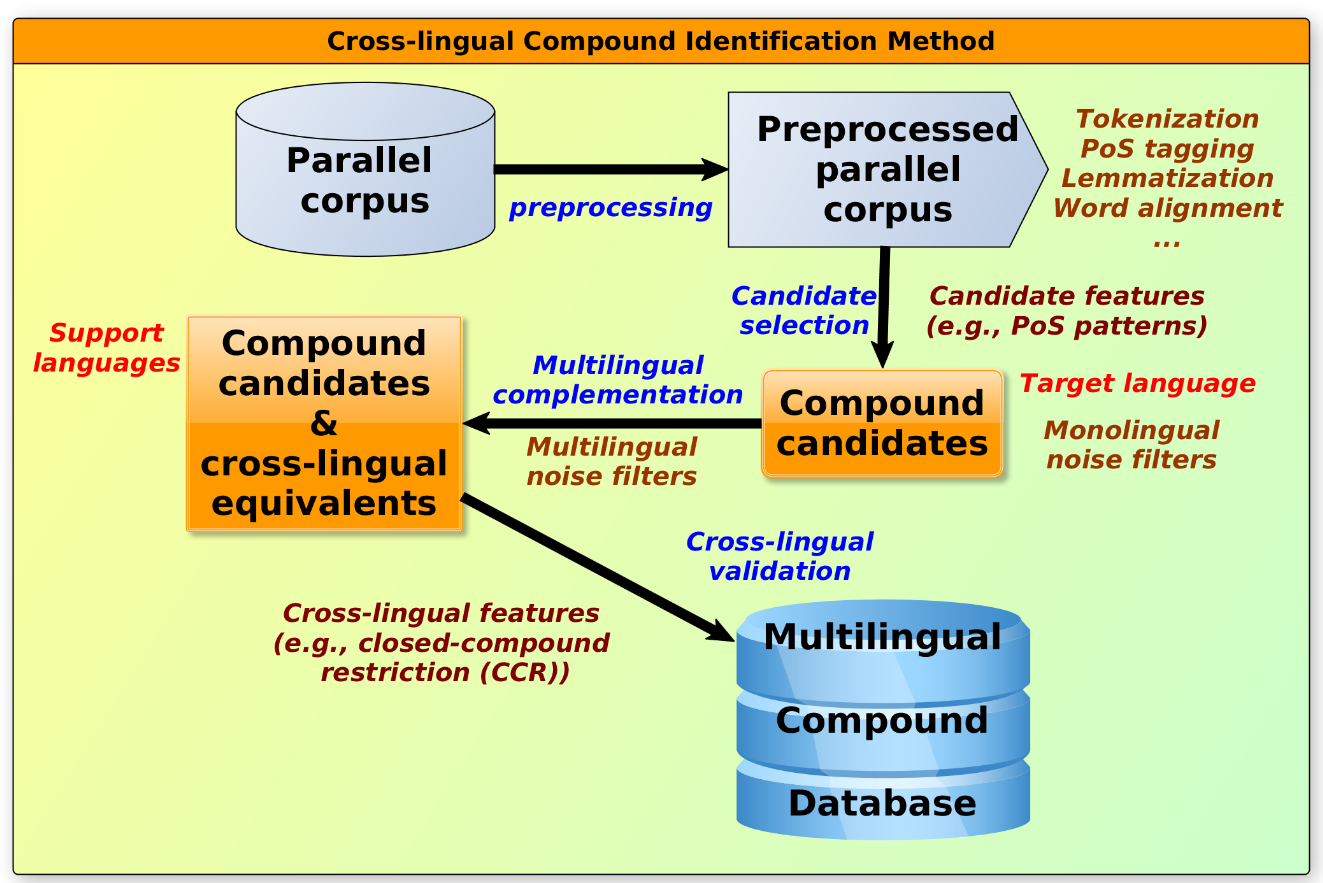
- A parallel corpus is transformed into a basic format.
In the current implementation, we focus on parallel corpora from OPUS (Tiedemann, 2012 [3]).
Other types of parallel have to be transformed into the basic format externally. - From the preprocessed parallel corpus, we identify candidate compounds for a target language TL based on candidate features (described in so-called candidate descriptions (CDs)).
- For all candidate compounds, we add their cross-lingual equivalents in different support languages SLs, based on automatic word alignments. These alignments can suffer from noise. Thus, we add a universal rule-based improvement step in order to get more correct cross-lingual equivalents.
- In the final step, all candidate compounds are scored based on cross-lingual evidence in terms of relative frequency of Germanic one-word equivalents, Germanic closed-compound equivalents and Romance multi-word equivalents.
The final output of the XCID can be restricted to compounds above a given threshold.
Main Modes
There are six main modes: RESOURCE (mainly for transforming an OPUS parallel corpus into the basic format), CANDIDATE SELECTION (for selecting potential candidate compounds based on candidate descriptions (CDs)), MULTILINGUAL COMPLETION (for enriching the compound resource with cross-lingual equivalents), SCORING CANDIDATE (for scoring all candidate compounds based on cross-lingual evidence), EXPLORER (for exploring the compound resource and showing compounds above a given score threshold), INFORMATION (for providing information for a given ID (e.g., what forms, attributes and context can be retrieved from the database for this ID)) and HELP (a help page as shown below).
RESOURCE
The resource compiler is designed for a parallel OPUS corpus (e.g., Europarl). The input depends on the submode: e.g., a folder with languages and corresponding (tokenized!) XML files, a folder with language pairs containing IDs and grow-diag-final-and GIZA analysis files, a folder with languages and corresponding basic documents (BDs) or the output of a preprocessing tool for enriching tokens in BDs with attributes (e.g., compound splits from MCS).
There are various submodes:
(1) improvement of the tokenization in xml files from OPUS (--RESOURCE XML)
(2) creation of basic format documents (--RESOURCE BD)
(3) creation of basic format word alignments (--RESOURCE BWA)
(4) creation of a list of terms and corpus frequencies for a given BD folder (--RESOURCE TERMS)
(5) addition of splitting information provided by the MOP-Compound Splitter (--RESOURCE MCS)Usage:
(1) java -jar XCID.jar --RESOURCE XML --XMLs <OPUS xml folder> --LANGUAGES <list of space-separated languages>
(2) java -jar XCID.jar --RESOURCE BD --XMLs <OPUS xml folder> --OUTPUT <OUTPUT folder for the basic format> --LANGUAGES <list of space-separated languages>
(3) java -jar XCID.jar --RESOURCE BWA --BDs <basic documents' folder> --ALIGNMENTS <OPUS word alignment folder> --OUTPUT <OUTPUT folder for the basic format> --LANGUAGES <list of space-separated languages>
optional: --PIVOT For considering BWAs only for language pairs containing a certain pivot language (e.g., English)(4) java -jar XCID.jar --RESOURCE TERMS --BDs <basic documents' folder> --OUTPUT <OUTPUT folder for the languages' term-frequency lists> --LANGUAGES <list of space-separated languages>
The term frequencies will be used as input for the crosslingual word alignment correction (for distinguishing function and content words). The list of terms can be used as collection by MCS. The MCS provides a trees file as output which can be used in submode (5).(5) java -jar XCID.jar --RESOURCE MCS --BDs <basic documents' folder> --LANGUAGE <the compound-splitting language> --OUTPUT <OUTPUT folder for the compound-split BDs> --TREES <the trees file given as output by the MCS>
CANDIDATE SELECTION
This mode selects potential candidate compounds based on candidate descriptions (CDs), i.e., usually sequences of PoS patterns.
Candidate Descriptions (CDs) file syntax:
[attribute_i=value_1|...|value_n] stands for a token having n possible values of the attribute_i
[attribute_i=value_j] [attribute_i=value_k] stands for two tokens with the specified attribute-value pairs
[attribute_i=value_j] & [attribute_m=value_n] stands for one token with two specified attribute-value pairs.
Usually, the attribute is the PoS annotation layer (e.g., from "tree"-tagger) and the values are possible PoS tags (e.g., proper names, common nouns, adjectives, etc. depending on the tag set).
Each CD is written in one line.
Examples:
[complex=true]&[tree=NP|NPS|NN|NNS] stands for a split proper name or common noun (singular or plural), based on Tree-Tagger
[tree=NP|NPS|NN|NNS|JJ|JJS|JJR|VBG|VVG] [tree=NP|NPS|NN|NNS] stands for a adjectival/nominal token followed by a nominal token, based on Tree-Tagger.Usage:
java -jar XCID.jar --CANDIDATES --CDs <file with candidate descriptions> --BDs <folder with language subfolders of basic documents> --OUTPUT <output folder> --LANGUAGE <the target language>
MULTILINGUAL COMPLETION
This main mode is responsible for enriching the compound resource with cross-lingual equivalents. There are two submodes:
(1) the collecting of all equivalents based on the word ALIGNMENTS from target language (e.g., English) to a certain aligned language
(2) the rule-based CORRECTION of various regular word alignment errors. The currently implemented rules towards correcting word alignment errors are: (i) Sub-compound filter (filters alignments to closed compounds of larger target compounds; e.g., (Football) 'World Cup' aligned to the German 'Fu??ballweltmeisterschaft'), (ii) Truncation of border function words (based on word frequency; e.g., the German 'Fu??ballweltmeisterschaft (von)') and (iii) Addition of internal function words (based on word frequency; e.g., the German 'Ausf??hrungen (von einer) Minute').Usage:
(1) java -jar XCID.jar --CROSSLINGUAL ALIGNMENTS --OUTPUT <OUTPUT folder for the cross-lingual alignment files> --CANDIDATEs <folder with language subfolders of candidates>
--BDs <folder with language subfolders of basic documents> --BWAs <folder with language pair subfolders of basic word alignments> --TL <the target language> --ALs <list of space-separated aligned languages>
(2) java -jar XCID.jar --CROSSLINGUAL CORRECTIONS --OUTPUT <OUTPUT folder for the cross-lingual alignment corrections> --XAs <folder with the cross-lingual alignments of previous step>
--BDs <folder with language subfolders of basic documents> --BWAs <folder with language pair subfolders of basic word alignments> --TL <the target language> --TERMs <the folder with all TERM-Frequency-distribution (from resource option) for all aligned languages>
SCORING CANDIDATE
This main mode scores all candidate compounds from the cross-lingual alignment corrections (i.e., XAC files).
Usage:
java -jar XCID.jar --SCORING --XACs <folder for cross-lingual alignment corrections, separated by languages> --OUTPUT <OUTPUT folder for the basic format> --TL <target language> --BDs <basic documents' folder>
The output are scored files, tab-separated values:
* Candidate compound ID
* Candidate compound form
* Number of one-word alignments among closed-compounding support languages
* Number of closed-compound alignments among closed-compounding support languages
* Number of closed-compounding support languages
* Relative frequency of one-word alignments among closed-compounding support languages
* Relative frequency of closed-compound alignments among closed-compounding support languages
* Number of multi-word alignments among open/non-compounding support languages
* Number of open/non-compounding support languages
* Relative frequency of multi-word alignments among open/non-compounding support languages
* Final score = product of all relative frequencies above
EXPLORER
This main mode allows for exploring the final resource (based on the scoring files, the cross-lingual corrections and the basic documents. It can be used for showing compounds with a specific score and their attributes, as well as the information about aligned equivalents. The output can be a file (one file for all score files; NOT gzipped this time!) or on the standard output.
Selective criteria:
--ST <score threshold> Only compounds having at least this score
--PP <PoS sequence> Only compounds whose PoS tags match this pattern
--RE <regular expression> Only compounds whose form matches this regular expression
--LE <true language equivalents> Only compounds that have a valid alignment in the specified languages (list of languages).
Additional information:
--TC <boolean> Show the context (i.e., the surrounding sentence) of the target compound
--TA <attributes of the target> For the target compound, show these attributes (list of attributes)
--AL <aligned languages> Show the ID and form of these aligned languages (list of languages; not necessarily the same as for --LE!)
--AA <attributes of aligned languages> For the aligned equivalent, show these attributes (list of attributes)
--AC <boolean> Show the context (i.e., the surrounding sentence) of the aligned equivalentsUsage:
java -jar XCID.jar --EXPLORER --TL <target language> --SCOREs <folder for scoring files> {selective criteria} {additional information}
INFORMATION
This main mode provides information for a given ID (e.g., what forms, attributes and context can be retrieved from the database for this ID).
Usage:
java -jar XCID.jar --TARGET <ID of the target compound> --BDs <basic documents' folder> --TYPE <a list of types which will be printed out for the targetID>
TYPEs:
FORM The form of the word sequence denoted by the targetID
ATTRIBUTE The attributes of the word sequence denoted by the targetID
SENTENCE The sentence surrounding the word sequence denoted by the targetID
SENTENCEATTRIBUTE The attributes of the sentence surrounding the word sequence denoted by the targetID
HELP
A detailed description of the usage is given in the help page.
Usage examples
java -jar XCID.jar --HELP
java -jar XCID.jar --HELP RESOURCE
java -jar XCID.jar --HELP CANDIDATES
java -jar XCID.jar --HELP CROSSLINGUAL
java -jar XCID.jar --HELP SCORING
java -jar XCID.jar --HELP EXPLORER
java -jar XCID.jar --HELP INFORMATION
- A parallel corpus is transformed into a basic format.
- Reference
-
[1] Patrick Ziering and Lonneke van der Plas
What good are 'Nominalkomposita' for 'noun compounds':
Multilingual Extraction and Structure Analysis of Nominal Compositions using Linguistic Restrictors
Proceedings of the 25th International Conference on Computational Linguistics (COLING), 2014.
[2] Patrick Ziering
Indirect Supervision for the Determination and Structural Analysis of Nominal Compounds
PhD thesis, 2018.
[3] J??rg Tiedemann
Parallel data, tools and interfaces in OPUS.
Proceedings of the Eight International Conference on Language Resources and Evaluation (LREC), 2012. - Download
-
Main Program: XCID.jar
Candidate Descriptions (for English): EnglishNominalCompoundCandidates.CDs
OPUS Corpora: Europarl DGTEuroparl:
- basic documents (the basic format)
- basic word alignments (the basic format)
- candidate compounds (output of candidate selection)
- cross-lingual alignments (output of multilingual completion)
- cross-lingual corrected alignments (output of rule-based alignment correction)
- scored compounds (output of scoring; revised version of the ENCD)
- XCID-output.EP.tsv
- XCID-output.EP-2NCs.tsv
- XCID-output.EP-3NCs.tsv
DGT:
- basic documents (the basic format)
- basic word alignments (the basic format)
- candidate compounds (output of candidate selection)
- cross-lingual alignments (output of multilingual completion)
- cross-lingual corrected alignments (output of rule-based alignment correction)
- scored compounds (output of scoring; revised version of the ENCD)
- XCID-output.DGT.tsv
- XCID-output.DGT-2NCs.tsv
- XCID-output.DGT-3NCs.tsv
- Data Format
-
Basic Format:
Basic documents:
File format:
token-ID <tab> word form <tab> attributes (from OPUS xml files or other sources such as the MCS) in the form attribute1="value1" <space> ... <space> attributen="valuen"
Examples:
DGT: 12005S.de.BD.gz
18 DIE s="3" lem="die" complex="false" tree="ART" id="w3.1"
19 HOHEN LSF2="Hohe~en" s="3" lem="hoch" complex="true" tree="ADJA" id="w3.2"
20 VERTRAGSPARTEIEN LSF2="Vertrag~Partei" s="3" lem="Vertragspartei" complex="true" tree="NN" id="w3.3"Basic Word Alignments:
File format:
token-ID of language A <tab> token-ID of language B
Examples:
DGT: 12005S.de.BD.gz..12005S.en.BD.gz..de..en.BWA.gz
18 <tab> 20
19 <tab> 21
20 <tab> 22
General Contact IMS
Pfaffenwaldring 5 b, 70569 Stuttgart
Webmaster of the IMS
- Write e-mail
- If you have any problems with the website, please directly contact the webmaster.