If you want to find out about the collocations a word occurs in, TIGERSearch allows you to compile frequency tables from text corpora - as an input to your lexicographic work. For example:
| 1. Choose a text corpus to search on
First, you have to choose a text corpus to search on. In our case, we may select the TIGER sampler corpus because it is shipped with the downloadable version of TIGERSearch. |
 |
|
| 2. Type in the query
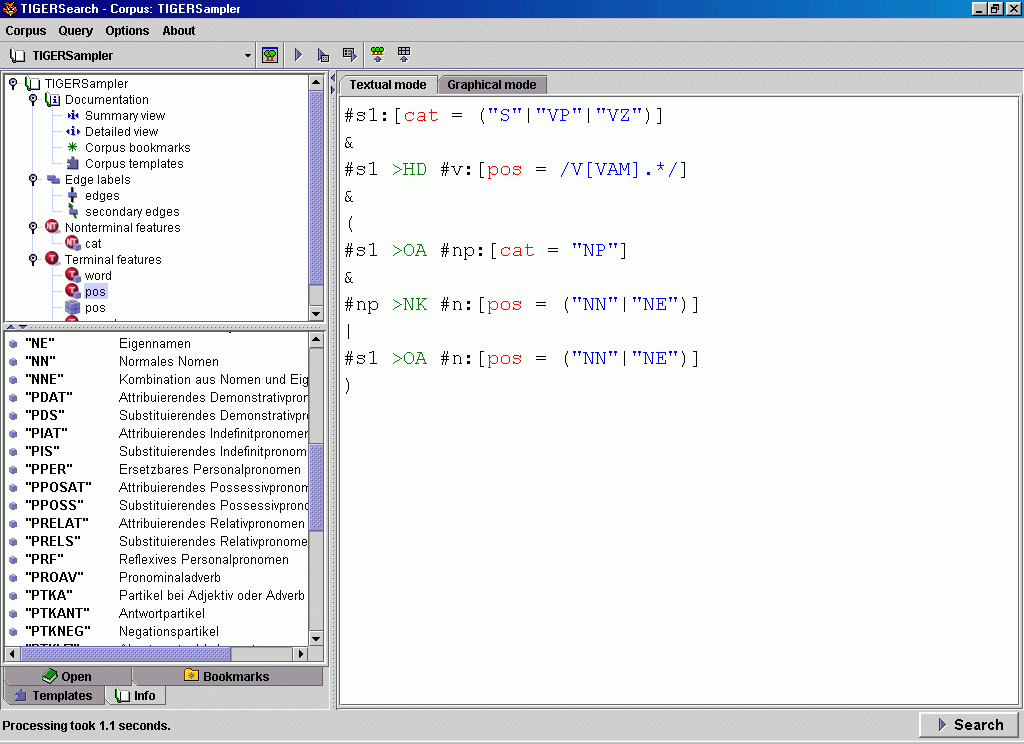
Let's search for verbs (V) and their (prefered) accusative objects. Our query has to take into account the given corpus annotation, i.e. the annotation conventions of the TIGER sampler corpus. There, nouns (NN) or proper names (NE) by themselves are directly linked by an object edge (OA) to the sentence node (S etc.) which dominates the head (HD), i.e. main verb of that sentence, whereas in the case of complex noun phrases, an explicit NP-node takes the OA-role. |
 |
|
| 3. View the frequency distribution
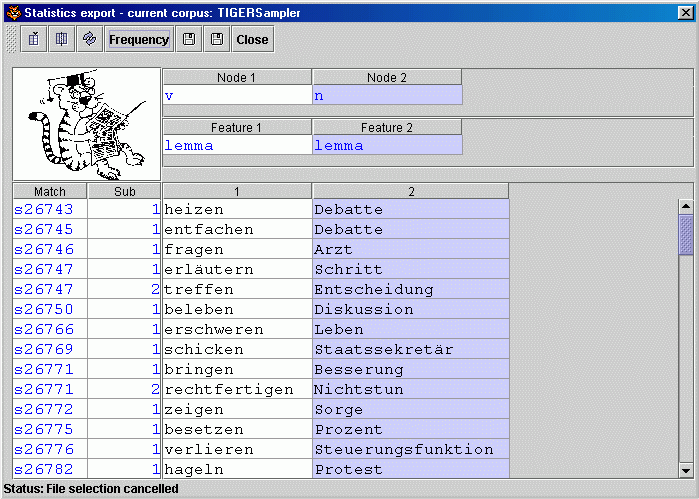
The 'statistics export' module can display e.g. the pairwise frequencies of the nodes which have been marked in the query as #v and #n, i.e. verb lemmata and the noun lemmata which occur in the corresponding accusative slot. Although the TIGER sampler corpus comprises only 200 sentences, we get an idea about typical verb-noun co-occurrences ("Entscheidung treffen", "Protest hageln", ...) |
 |