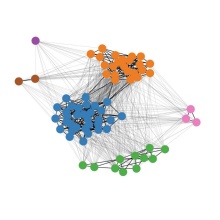
Word Usage Graphs
Word Usage Graphs (WUGs) represent usages of a word as nodes in a graph which are connected by weighted edges representing (human-annotated) semantic proximity. We list various WUG resources below. These can be exploited in various ways, e.g. as resources of thousands of word use pair semantic proximity judgments or as clustered graph representations of word use sets. As such they provide various possibilities to evaluate computational lexical semantic models (e.g. contextualized embeddings, word sense disambiguation/discrimination) with additional aspects such as variation over time or dialect.
Find the idea behind WUGs described in this blog article. Also, consider the DURel annotation tool to annotate your own WUGs and enriched WUGs with cluster definitions. Find further information on the format and code to process the data below.
Each resource contains the following data:
- readme: containing information specific to the resource.
- annotators: a list of all (anonymized) annotators.
- guidelines: used to train annotators.
- data: for each word including
- uses: with the main use in the column 'context' as a spelling-normalized version of 'context_tokenized' (see code below). The column 'indexes_target_token' gives the character indexes of the target token in 'context' (Python list ranges as used in slicing), while the column 'indexes_target_sentence' gives the character indexes of the target sentence (containing the target token) in 'context'. Similarly, the columns 'indexes_target_token_tokenized' and 'indexes_target_sentence_tokenized' contain the token indexes of target token and sentence in the tokenized, lemmatized and POS-tagged version of the word use (after splitting at whitespaces). We provide meta-information on each use (POS, date, etc.) and tokenized, lemmatized and POS-tagged versions if available.
- judgments: human semantic proximity judgments of use pairs.
- senses (optional): sense descriptions, if available. Annotators had the choice to assign uses to a generic sense description 'andere' ('others').
- judgments_senses (optional): judgments of sense descriptions for uses, if available. If no judgment was provided by an annotator the column 'identifier_sense' contains the string 'None'.
- graphs: WUGs derived from the annotated data as Python NetworkX objects (see code). The folder
full/contains the full graphs with all nodes and edges without clustering.opt/contains the latest cleaned and optimized version including a clustering obtained with optimized parameters (see code). Additionally, we provide versions of the graphs related to previous publications (e.g.semeval/). - clusters: clusterings extracted from the respective graphs.
- plots: two-dimensional visualizations of the respective graphs. Clusters are visualized as nodes with the same color (additionally marked by common numbers in nodes to avoid confusion of colors). Black edges mark median judgments with values above the chosen threshold for clustering (e.g. 2.5), while gray edges mark median judgments below that threshold. We provide various versions of the plots with different edge labels (e.g. edges labeled with all their judgments or only the median judgment respectively). Nodes contain the context of the corresponding word use with additional meta-information. Nodes can be moved by clicking and dragging. We also provide visualizations of subgraphs corresponding to each grouping of the nodes as specified in the use files (e.g. time periods) and pairwise aligned versions for each combination of groupings. Mozilla Firefox is often a good choice to open the visualizations.
- stats: statistics derived from the respective graphs including clustering statistics. We also report statistics concerning the comparison of clusterings between groupings including change scores as well as annotator agreement.
Additional data may be provided for individual resources, as specified in their readme.
All text files are tab-separated and use UTF-8 encoding. Quotes do not mark strings, but are part of the original contexts.
We provide code to create, process and cluster the graphs in the WUG repository. We also provide a script loading and visualizing the most recent datasets.
Dominik Schlechtweg. 2023. Human and Computational Measurement of Lexical Semantic Change. PhD thesis. University of Stuttgart.
German
- language: German
- groupings: 1800-1899, 1946-1990
- judgments: 63k
- download
- reference: Dominik Schlechtweg, Nina Tahmasebi, Simon Hengchen, Haim Dubossarsky, Barbara McGillivray. 2021. DWUG: A large Resource of Diachronic Word Usage Graphs in Four Languages. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing.
- language: German
- groupings: 1800-1899, 1946-1990
- judgments: 10k
- download
- reference: Dominik Schlechtweg, Pierluigi Cassotti, Bill Noble, David Alfter, Sabine Schulte im Walde, Nina Tahmasebi. More DWUGs: Extending and Evaluating Word Usage Graph Datasets in Multiple Languages. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing.
- language: German
- groupings: 1800-1899, 1946-1990
- judgments: 3.5k
- download
- reference: Dominik Schlechtweg, Frank D. Zamora-Reina, Felipe Bravo-Marquez, Nikolay Arefyev. 2024. Sense Through Time: Diachronic Word Sense Annotations for Word Sense Induction and Lexical Semantic Change Detection. Language Resources and Evaluation.
- language: German
- groupings: 1800-1899, 1946-1990
- judgments: 28k
- download
- reference: Sinan Kurtyigit, Maike Park, Dominik Schlechtweg, Jonas Kuhn, Sabine Schulte im Walde. 2021. Lexical Semantic Change Discovery. Proceedings of the Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing.
- language: German
- groupings: 1750-1800, 1850-1900
- judgments: 4k
- download
- reference: Dominik Schlechtweg. 2023. Human and Computational Measurement of Lexical Semantic Change. PhD thesis. University of Stuttgart.
- language: German
- groupings: 1750-1800, 1850-1900
- judgments: 6k
- download
- reference: Dominik Schlechtweg, Sabine Schulte im Walde, Stefanie Eckmann. 2018. Diachronic Usage Relatedness (DURel): A Framework for the Annotation of Lexical Semantic Change. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 169-174.
- language: German
- groupings: general, domain-specific
- judgments: 5k
- download
- reference: Anna Hätty, Dominik Schlechtweg, Sabine Schulte. 2019. SURel: A Gold Standard for Incorporating Meaning Shifts into Term Extraction. Proceedings of the 8th Joint Conference on Lexical and Computational Semantics, 1-8.
English
- language: English
- groupings: 1810-1860, 1960-2010
- judgments: 69k
- download
- reference: Dominik Schlechtweg, Nina Tahmasebi, Simon Hengchen, Haim Dubossarsky, Barbara McGillivray. 2021. DWUG: A large Resource of Diachronic Word Usage Graphs in Four Languages. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing.
- language: English
- groupings: 1810-1860, 1960-2010
- judgments: 7k
- download
- reference: Dominik Schlechtweg, Pierluigi Cassotti, Bill Noble, David Alfter, Sabine Schulte im Walde, Nina Tahmasebi. More DWUGs: Extending and Evaluating Word Usage Graph Datasets in Multiple Languages. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing.
- language: English
- groupings: none
- judgments: 9k
- note: find scripts to convert the data under code above
- download
- reference: Katrin Erk, Diana McCarthy, Nicholas Gaylord. 2013. Measuring Word Meaning in Context. Computational Linguistics 39 (3), pp. 511-554.
- language: English
- groupings: 1910-1920, 1930-1940, 1950-1960, 1970-1980, 1990-2000
- judgments: 16k
- download
- reference: Mario Giulianelli, Marco Del Tredici, and Raquel Fernández. 2020. Analysing lexical semantic change with contextualised word representations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 3960–3973, Online. Association for Computational Linguistics.
Russian
- language: Russian
- groupings: 1682-1916, 1918-1990, 1991-2016
- judgments: 8k
- download
- reference: Julia Rodina, Andrey Kutuzov. 2020. RuSemShift: a dataset of historical lexical semantic changes in Russian. Proceedings of the 28th International Conference on Computational Linguistics. Association for Computational Linguistics, Barcelona, Spain.
- language: Russian
- groupings: 1682-1916, 1918-1990, 1991-2016
- judgments: 30k
- download
- reference: Andrey Kutuzov, Lidi Pivovarova. 2021. Three-part diachronic semantic change dataset for Russian. In Proceedings of the 2nd International Workshop on Computational Approaches to Historical Language Change.
- language: Russian
- groupings: none
- judgments: 6k
- download
- reference: Anna Aksenova, Ekaterina Gavrishina, Elisei Rykov, and Andrey Kutuzov. 2022. RuDSI: Graph-based Word Sense Induction Dataset for Russian. In Proceedings of TextGraphs-16: Graph-based Methods for Natural Language Processing.
Spanish
- language: Spanish
- groupings: 1810-1906, 1994-2020
- judgments: 62k
- download
- reference: Frank D. Zamora-Reina, Felipe Bravo-Marquez, Dominik Schlechtweg. 2022. LSCDiscovery: A shared task on semantic change discovery and detection in Spanish. In Proceedings of the 3rd Workshop on Computational Approaches to Historical Language Change.
- language: Spanish
- groupings: 6 contemporary Spanish variants
- judgments: 8k
- download
- reference: Gioia Baldissin, Dominik Schlechtweg, Sabine Schulte im Walde. submitted. DiaWUG: A Dataset for Diatopic Lexical Semantic Variation in Spanish. In Proceedings of the Thirteenth Language Resources and Evaluation Conference.
Swedish
- language: Swedish
- groupings: 1790-1830, 1895-1903
- judgments: 55k
- download
- reference: Dominik Schlechtweg, Nina Tahmasebi, Simon Hengchen, Haim Dubossarsky, Barbara McGillivray. 2021. DWUG: A large Resource of Diachronic Word Usage Graphs in Four Languages. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing.
- language: Swedish
- groupings: 1790-1830, 1895-1903
- judgments: 16k
- download
- reference: Dominik Schlechtweg, Pierluigi Cassotti, Bill Noble, David Alfter, Sabine Schulte im Walde, Nina Tahmasebi. More DWUGs: Extending and Evaluating Word Usage Graph Datasets in Multiple Languages. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing.
- language: Swedish
- groupings: 2004-2012, 2013-2021
- judgments: 437k
- download
- reference: Dominik Schlechtweg, Emma Sköldberg, Shafqat Mumtaz Virk, James White, Simon Hengchen. 2025. Automatic Non-recorded Sense Detection for Swedish through Word Sense Induction with fine-tuned Word-in-Context models. Proceedings of the 9th eLex conference Electronic lexicography in the 21st century: Intelligent Lexicography.
Other languages
- language: Mandarin Chinese
- groupings: 1954-1978, 1979-2003
- judgments: 61k
- download
- reference: Jing Chen, Emmanuele Chersoni, Dominik Schlechtweg, Jelena Prokic, Chu-Ren Huang. 2023. ChiWUG: A Graph-based Evaluation Dataset for Chinese Lexical Semantic Change Detection. Proceedings of the 4th International Workshop on Computational Approaches to Historical Language Change 2023 (LChange'23).
- language: Italian
- groupings: 1948-1970, 1990-2014
- judgments: 5k
- download
- reference: Pierluigi Cassotti, Pierpaolo Basile, Nina Tahmasebi. 2024. DWUGs-IT: Extending and Standardizing Lexical Semantic Change Detection for Italian. Proceedings of the 10th Italian Conference on Computational Linguistics.
- language: Latin
- groupings: -200-0, 0-2000
- judgments: 9k
- download
- reference: Dominik Schlechtweg, Nina Tahmasebi, Simon Hengchen, Haim Dubossarsky, Barbara McGillivray. 2021. DWUG: A large Resource of Diachronic Word Usage Graphs in Four Languages. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing.
- language: Norwegian
- groupings: 1929-1965, 1970-2013, 1980-1990, 2012-2019
- judgments: 19k
- download
- reference: Andrey Kutuzov, Samia Touileb, Petter Mæhlum, Tita Enstad, and Alexandra Wittemann. 2022. NorDiaChange: Diachronic Semantic Change Dataset for Norwegian. In Proceedings of the Thirteenth Language Resources and Evaluation Conference.
Related Resources
- access
- reference: Dominik Schlechtweg, Shafqat Mumtaz Virk, Pauline Sander, Emma Sköldberg, Lukas Theuer Linke, Tuo Zhang, Nina Tahmasebi, Jonas Kuhn, Sabine Schulte im Walde. 2024. The DURel Annotation Tool: Human and Computational Measurement of Semantic Proximity, Sense Clusters and Semantic Change. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations.
- code and models
- reference: Dominik Schlechtweg, Enrique Castaneda, Jonas Kuhn, Sabine Schulte im Walde. 2021. Modeling Sense Structure in Word Usage Graphs with the Weighted Stochastic Block Model. In Proceedings of the 10th Joint Conference on Lexical and Computational Semantics.
- data and code
- reference: Mariia Fedorova, Andrey Kutuzov, Nikolay Arefyev, Dominik Schlechtweg. 2024. Enriching Word Usage Graphs with Cluster Definitions. The 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation.
- language: German, English, Latin, Swedish
- download
- reference: Dominik Schlechtweg, Barbara McGillivray, Simon Hengchen, Haim Dubossarsky, Nina Tahmasebi. 2020. SemEval-2020 Task 1: Unsupervised Lexical Semantic Change Detection. Proceedings of the 14th International Workshop on Semantic Evaluation.

Dominik Schlechtweg
Dr.Postdoktorand

Sabine Schulte im Walde
Prof. Dr.Akademische Rätin