MOP Compound Splitter (MCS)
Typ
Autor
Beschreibung
This system is a compound splitter based on constituent normalization using Morphological Operation Patterns (MOPs).
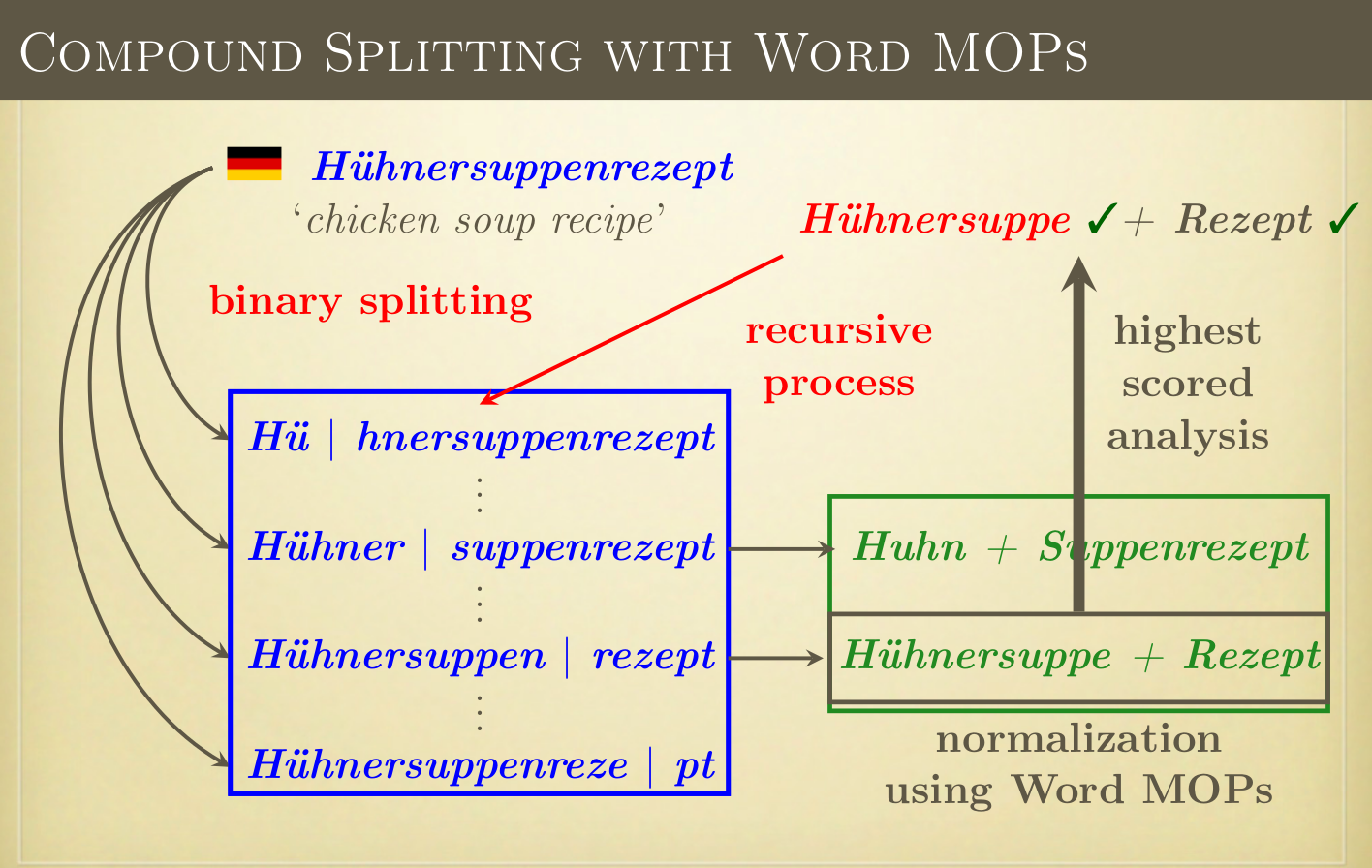
As core splitting method it uses a recursive frequency-based architecture, inspired by [1] Koehn and Knight (2003). The usage of MOPs learned from regular word inflection (i.e., Word MOPs) allows for compound splitting in many languages without the need for language-specific knowledge about constituent inflection. We developed models for various languages compound splitting (i.e., MOPs and lemma sets, as can be found below for download). We evaluated models for German, Dutch and Afrikaans.
For models in further closed-compounding languages, please contact me!
The MCS is described in [2] Ziering and Van der Plas (2016) and [3] Ziering (2018).
Main Modes
There are four main modes: RESOURCE (for collecting lemma frequency, part-of-speech (PoS) probabilities and MOPs from a PoS-tagged and lemmatized corpus, as resources for the compound splitter), SPLIT (for MOP-based compound splitting), MOP (for testing the potential of MOPs) and HELP (a help page containing all relevant arguments and options).
RESOURCE
The purpose of this mode is to compile a lemma set (containing lemmas with corpus frequency and PoS probability) and an MOP set (containing all MOPs used for transforming a lemma into its corresponding word form with corpus frequency and PoS probability). Input file format: word <tab> PoS <tab> lemma; one token per line. The output are a lemma set and an MOP set.
Usage example
java -jar MCS.jar --RESOURCE --CORPUS <corpus file>
SPLITTING
This mode is the core method of MCS, the MOP-based compound splitter that generates a linear and a hierarchical structure of a given target compound. As resources, it uses a lemma set and an MOP set. Depending on the language, the user can distinguish between MOPs for the head and for the modifier. There are three different kinds of input: TERM (for a single term), TEXT (for a tokenized text file) and COLLECTION (for a list of target compounds, one per line). There are various additional options, described in the help page (java -jar MCS.jar --HELP SPLITTING).
Output format
There are two different types of output for several numbers of constituents and rankings: (1) TREE OUTPUT and (2) BINARY SPLIT OUTPUT.
The format of the TREE OUTPUT is:
<number of constituent>@<ranking> =T <score/null> <number of constituent> <target compound> <split point format> <linear lemma format> <bracketing lemma format>
For example, splitting "Hühnersuppenrezept" (chicken soup recipe) yields:
3@1#>>>>>> =T null 3 Hühnersuppenrezept hühner|suppen|rezept Huhn Suppe Rezept [ [ Huhn Suppe ] Rezept ]
2@1#>>>>>> =T null 2 Hühnersuppenrezept hühnersuppen|rezept Hühnersuppe Rezept [ Hühnersuppe Rezept ]
In the current version, there is no score for trees, but only for binary split decisions. Providing scores for different tree structures (i.e., compound parsing) will be addressed in future work.
The format of the BINARY SPLIT OUTPUT is:
<number of constituent>@<ranking> =B <score> <number of constituent> <target compound> <split point format> <linear lemma format> <null>
For example, splitting "Gastraum" (guest room / gas dream?) into two constituents yields:
2@1#>>>>>> =B 421683.74529459066 2 gastraum gast|raum gast raum null
2@2#>>>>>> =B 98741.69382132468 2 gastraum gas|traum gas traum null
Usage examples
Splitting a term with two specified MOP sets with a verbose command line output:
java -jar MCS.jar --SPLIT --LEMMASET <lemma set file> --modifierMOPs <MOP set for the modifier> --headMOPs <MOP set for the head> --TERM <term to be split> --VERBOSE
Splitting a collection of terms (one per line) with MOPs for the modifier:
java -jar MCS.jar --SPLIT --LEMMASET <lemma set file> --modifierMOPs <MOP set for the modifier> --COLLECTION <collection file> --OUTPUT <substring for output files>
Splitting a (tokenized) text (several space-separated tokens per line) with MOPs for the modifier, lower-casing all tokens and a maximum splitting depth of 3 constituents
java -jar MCS.jar --SPLIT --LEMMASET <lemma set file> --modifierMOPs <MOP set for the modifier> --COLLECTION <collection file> --OUTPUT <substring for output files> --kmax 3
MOP
The purpose of this mode is to test the potential of MOPs, i.e., to COMPILE MOPs from two strings, to APPLY an MOP on a string, to INVERT an MOP and to LEMMATIZE a term/text/collection by using an word MOP set.
Usage examples
Compiling an MOP for transforming a given source term into a given target term:
java -jar MCS.jar --MOP --COMPILE --A <source term> --B <target term>
Applying a given MOP on a given term:
java -jar MCS.jar --MOP --APPLY <the MOP> --TERM <term>
Inverting a given MOP:
java -jar MCS.jar --MOP --INVERT <the MOP>
Lemmatizing a term using word MOPs:
java -jar MCS.jar --MOP --LEMMATIZE <word MOP set> --LEMMASET <lemma set file> --TERM <term>
HELP
A detailed description of the usage is given in the help page.
Usage examples
Main menu
java -jar MCS.jar --HELP
For the data processing and the creation of the resource (i.e., lemma set and MOP set), more information is given in
java -jar MCS.jar --HELP RESOURCE
For compound splitting, more information is given in
java -jar MCS.jar --HELP SPLITTING
For the MOP mode, more information is given in
java -jar MCS.jar --HELP MOP
Referenz
[1] Philipp Koehn and Kevin Knight.
Empirical Methods for Compound Splitting.
Proceedings of EACL 2003.
[2] Patrick Ziering and Lonneke van der Plas
Towards Unsupervised and Language-independent Compound Splitting
using Inflectional Morphological Transformations
Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), San Diego, USA, 2016.
[3] Patrick Ziering
Indirect Supervision for the Determination and Structural Analysis of Nominal Compounds
PhD thesis, 2018.
[4] Verena Henrich and Erhard W. Hinrichs
Determining Immediate Constituents of Compounds in GermaNet
RANLP, 2011.
[5] Stefan Langer
Zur Morphologie und Semantik von Nominalkomposita
KONVENS, 1998.
[6] Ben Verhoeven, Menno van Zaanen, Walter Daelemans and Gerhard B. van Huyssteen
Automatic Compound Processing: Compound Splitting and Semantic Analysis for Afrikaans and Dutch
ComAComA, 2014.
[7] Robert Östling
Stagger: an Open-Source Part of Speech Tagger for Swedish
Northern European Journal of Language Technology, 2013
Download
Main Program: MCS.jar
Instructions: README.txt
Automatic word MOPs:
- German Wikipedia
- Dutch Wikipedia
- Afrikaans Wikipedia
- Danish Wikipedia
- Swedish Wikipedia (trained with Stockholm Tagger (Stagger) [7])
- English Wikipedia (only for --headMOPs)
Splitting gold standard MOPs (use --ModifierMOPDomain ALL !):
- GermaNet (according to [4] Henrich and Hinrichs (2011))
- Dutch (according to [6] Verhoeven et al. (2014))
- Afrikaans (according to [6] Verhoeven et al. (2014))
Manual MOPs (use --ModifierMOPDomain ALL !):
Lemma sets:
- German Wikipedia
- Dutch Wikipedia
- Afrikaans Wikipedia
- Danish Wikipedia
- Swedish Wikipedia (trained with Stockholm Tagger (Stagger) [7])
- English Wikipedia
Kontakt IMS
Pfaffenwaldring 5 b, 70569 Stuttgart
- Weitere Informationen
- E-Mail schreiben
- Allgemeine Kontaktadresse des IMS
Webmaster des IMS
- E-Mail schreiben
- Bei Problemen mit den Webseiten kontaktieren Sie den Webmaster direkt