TIGERSearch
- Typ
-
Tool
- Beschreibung
-
TIGERSearch is not updated anymore. You may be interested in our new tool, ICARUS (Interactive platform for Corpus Analysis and Research tools, University of Stuttgart).
 Welcome to the TIGERSearch homepage! The TIGERSearch software let's you explore linguistically annotated texts. For example, a lexicographer or terminologist can use TIGERSearch to find out about lexical properties of a word like the collocations the word is used in. A linguist could employ TIGERSearch to obtain sample sentences for the syntactic phenomena he is interested in.
Welcome to the TIGERSearch homepage! The TIGERSearch software let's you explore linguistically annotated texts. For example, a lexicographer or terminologist can use TIGERSearch to find out about lexical properties of a word like the collocations the word is used in. A linguist could employ TIGERSearch to obtain sample sentences for the syntactic phenomena he is interested in.Technically speaking, TIGERSearch is a specialized search engine for retrieving information from a database of graph structures (usually called "treebank"). This means that the text ("text corpus") which is to be searched by TIGERSearch must have been annotated beforehand, e.g. with grammatical analyses ("syntax trees"). TIGERSearch gives linguists intuitive access to such specialized "linguistic databases":

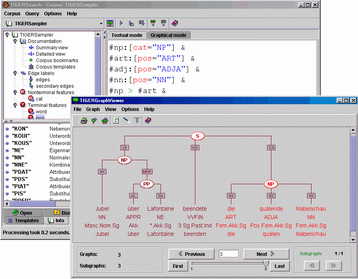
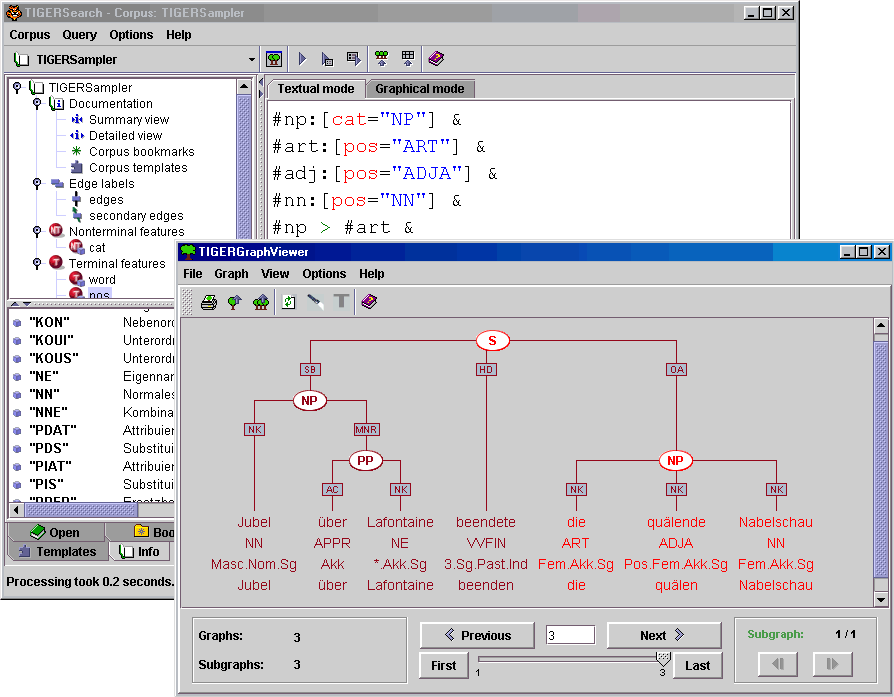
TIGERSearch is delivered with a carefully designed graphical user interface. Novices can formulate queries in an intuitive manner by 'drawing' partial graphs. Advanced users will prefer the textual query input, which is supported by syntax highlighting and various menus for choosing the correct feature names etc. for a given corpus. Query results (e.g. syntax trees) are displayed graphically by the TIGERSearch GraphViewer, which allows for convenient browsing of results. The query language of TIGERSearch incorporates elements which are well known from grammar formalisms in (computational) linguistics. A restricted kind of attribute-value structures are available. Type definitions can be used to structure the corpus nomenclature. Template definitions help to break down complex queries. TIGERSearch provides XML-based interfaces for advanced applications, both for corpus import and for the export of results. State-of-the-art technologies can be used to manipulate and to aggregate query results. Basic tools are included for frequency calculations, export of query results in kwic (keyword in context) format, etc. You can get a first impression of TIGERSearch by taking the guided tours for syntacticians and for lexicographers. An overview of the technical features is given in the TIGERSearch data sheet.
Manual: We provide a pdf version and an online version of the manual. In addition there is a JavaHelp verison of the manual integrated into the TIGERSearch application.
Contact: For further information please contact CLARIN-D at Stuttgart.
- Referenz
-
-
König, Esther; Lezius, Wolfgang (2003) The TIGER language - A Description Language for Syntax Graphs, Formal Definition. Technical report IMS, Universität Stuttgart, Germany. PDF
- König, Esther; Lezius, Wolfgang; Voormann, Holger (2003) TIGERSearch User's Manual IMS, University of Stuttgart Stuttgart. HTML
-
Lezius, Wolfgang (2002) Ein Suchwerkzeug für syntaktisch annotierte Textkorpora Ph.D. thesis IMS, University of Stuttgart Arbeitspapiere des Instituts für Maschinelle Sprachverarbeitung (AIMS), volume 8, number 4. PDF
- Lezius, Wolfgang (2002) TIGERSearch - Ein Suchwerkzeug für Baumbanken in Stephan Busemann, editor, Proceedings der 6. Konferenz zur Verarbeitung natürlicher Sprache (KONVENS 2002) Saarbrücken. PDF
- Voormann, Holger; Lezius, Wolfgang (2002) TIGERin - Grafische Eingabe von Benutzeranfragen für ein Baumbank-Anfragewerkzeug in Stephan Busemann, editor, Proceedings der 6. Konferenz zur Verarbeitung natürlicher Sprache (KONVENS 2002) Saarbrücken. PDF
-
König, Esther; Lezius, Wolfgang (2000) A description language for syntactically annotated corpora in Proceedings of the COLING Conference pp. 1056-1060 Saarbrücken, Germany. PDF
-
Mengel, Andreas; Lezius, Wolfgang (2000) An XML-based encoding format for syntactically annotated corpora in Proceedings of the Second International Conference on Language Resources and Engineering (LREC) volume 1 pp. 121-126 Athens, Greece. PDF
-
- Download
-
TIGERSearch is available free of charge under the GNU Public License.
Projekt CLARIN-D
- Weitere Informationen
- E-Mail schreiben
- Funktionsadresse